
ניווט לפי תוכן
עברה תקופה קצרה מהמאמר האחרון בתחום ה-SEO, אבל יש לי תירוץ טוב, נפלתי לפייתון, נפלתי חזק.
אני: שלום אני דודי, ואני מכור לפייתון.
קבוצה: אוהבים אותך דודי!
ואם נהיה רציניים לרגע, זו התמכרות שאני מקווה לא להיגמל ממנה, מכמה סיבות:
- צצים אתגרים חדשים על בסיס קבוע וזה לא תמיד כזה פשוט להתמודד איתם, אז כשזה מצליח זה סופר מוערך.
- אני מצליח לראות את כל התחום שלי – SEO, SMM, PPC ושיווק דיגיטלי בכלל באור שונה, זה מכריח אותי להסתכל על הדברים מנקודת מבט חדשה ואני מרגיש שזה מפתח אותי כמנהל מערך שיווק דיגיטלי.
- האופציות ב-Python הן אינסופיות, זה כלי שלא כולם יודעים להשתמש בו: ואיפה שלא כולם נמצאים, זו תמיד הזדמנות לזרוח.
בכתבה אסביר איך Python יכולה להתחבר לתחום ה-SEO (או השיווק הדיגיטלי) ולעזור לנו לקצר תהליכים בעזרת יצירת אוטומציות לתהליכים מעייפים שחוזרים על עצמם, לחסוך ואפילו להרוויח לנו כסף, או סתם להנות מאתגר חדש.
מי שרוצה רקע קצת יותר רחב על פייתון, מוזמן ללינק הויקיפדיה הבא:
https://he.wikipedia.org/wiki/פייתון
להתנסות הראשונה שלי ב-Python, החלטתי לכתוב על תהליך קצר שעברתי כשכתבתי קוד לסריקת אתר שאוסף פרמטרים לניתוח מבנה הלינקים הפנימיים באתר (נקרא גם עכביש), הקוד מייצא את הנתונים לאקסל, לי אישית קל יותר באקסל, שם ניתחתי את הנתונים וקיבלתי תובנות שעזרו לי לבנות תוכנית שיפורים, במקרה הזה מדובר באתר Cerve.co, שממנו קיבלתי אישור לסריקה בתנאי שאשתף את התובנות שמצאתי.
חברת Cerve.co מפתחת פלטפורמת הזמנות מתקדמת שהופכת מכירות של ספקי מזון לאוטומטיות, הפלטפורמה משתלבת באינטגרציה למערכות ERP ובכך היא מגדילה את הרווחיות והיעילות.
מוזמנים לקרוא עוד קצת על Cerve באתר הרשמי: https://cerve.co/help
כמו תמיד לפני שמתחילים, נקודות חשובות:
אזהרה! שימו לב כשאתם סורקים, לא לשלוח יותר מידי בקשות, זה יכביד על האתר ואתם עלולים להיחסם, כדי למנוע זאת עדיף להקטין את מספר הבקשות ולהגדיל את הפרשי הזמן ביניהן או להשתמש ב- Proxy ו-User Agent כמו זה של בוטים (Crawlers' Bots) או דפדפן שאתם לא משתמשים בו, לדוגמה:
- בוט של גוגל:
Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) - בוט של בינג:
Mozilla/5.0 (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm) - דפדפן Opera:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36 OPR/69.0.3686.49
צריכים עוד מבחר של User Agents?
https://developers.whatismybrowser.com/useragents/explore/software_name
כמו שהבנתם לא תהיה הדרכה בסיסית על Python וה-Syntax שלה, יש מספיק מידע בנושא כאן. בכתבה זו אפרט על בניית עכביש סריקה בסיסי לקריאת לינקים פנימיים באתר, איסוף מידע, מה צריך לבדוק, הבעיות שנתקלתי בהן, הפתרונות, התובנות מתוך ההתנסות האישית שלי, איך זה יכול לעזור בסיטואציות יותר מורכבות ולאן עוד אפשר להגיע עם פייתון.
העכביש מבוסס על Scrapy, שזוהי בעצם חבילת סריקה עם ביצועים מרשימים, מוזמנים לקרוא: https://scrapy.org/
אם רוצים לקצר, ישנה דרך פשוטה להתחיל פרוייקט ב-Scrapy, אפשר לתת ל-Scrapy ליצור את המבנה והקבצים, פה יש עוד מידע בנושא: https://docs.scrapy.org/en/latest/intro/tutorial.html#creating-a-project
כתיבת הקוד
לפני שהתחלתי לכתוב את הקוד, הכנתי תרשים שיעזור לי להכין את עצמי טוב יותר לכתיבה:
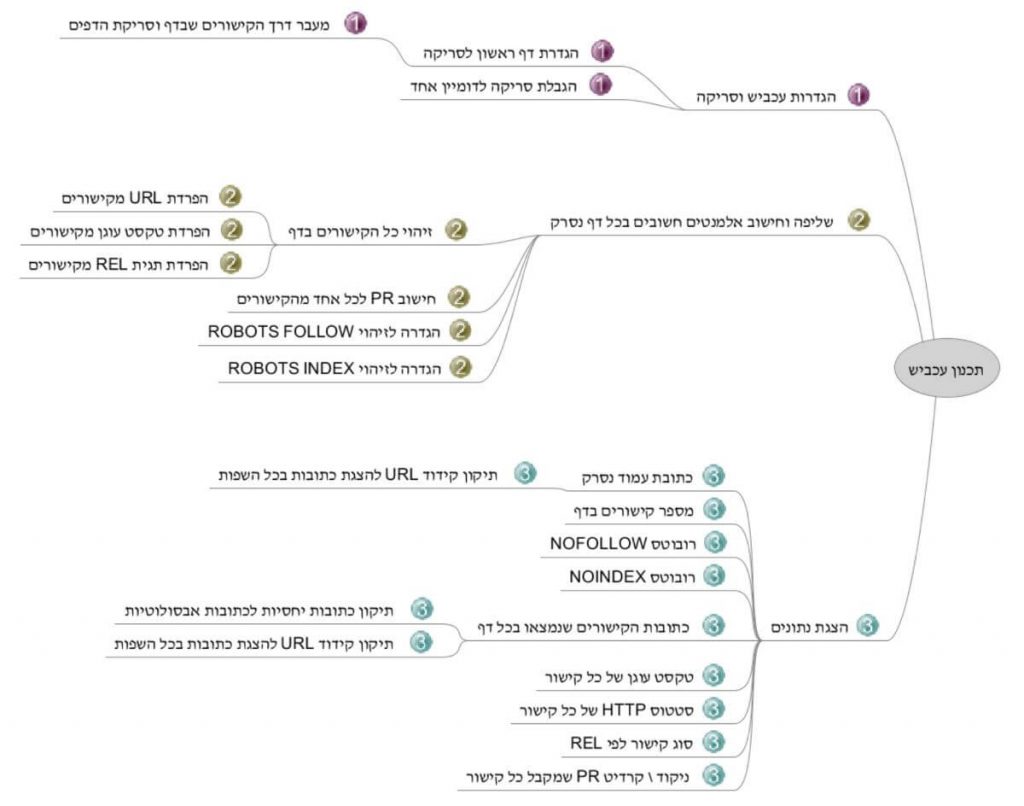
לפי השלבים שבתרשים, הרבה קריאה ולמידת הסינטקס של Python ו-Scrapy, כך נראה הקוד הסופי:
import scrapy
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
import urllib.parse
import requests
class TestSpider(CrawlSpider):
name = "test"
allowed_domains = ["cerve.co"]
start_urls = ["https://cerve.co"]
rules = [Rule (LinkExtractor(allow=['.*'], tags='a', unique=True), callback='parse_item', follow=True)]
def parse_item(self, response):
alllinks = response.css('a')
PRscore = 1 / len(alllinks)
if "nofollow" in response.css('head meta[name="robots"]::attr(content)').get('content'):
mrfollow = 'nofollow'
else:
mrfollow = 'follow'
if "noindex" in response.css('head meta[name="robots"]::attr(content)').get('content'):
mrindex = 'noindex'
else:
mrindex = 'index'
for link in alllinks:
href = link.css('a::attr(href)').get()
anchor = link.css('a::text').get()
rel = link.css('a::attr(rel)').get()
yield {
'page': urllib.parse.unquote(response.url),
'number of links': len(alllinks),
'meta robots follow': mrfollow,
'meta robots index': mrindex,
'links': urllib.parse.unquote(response.urljoin(href)),
'anchor': anchor,
'link-rel': rel,
'status': requests.get(response.urljoin(href)).status_code,
'page rank score': PRscore
}
פירוט והסברים
בפייתון אפשר לכתוב את הקוד מאפס או להיעזר בחבילות שמקצרות את כתיבת הקוד ומפשטות תהליכים מורכבים, זו לא תמיד הדרך הכי טובה, לפעמים כדאי לכתוב את הקוד מההתחלה ולבנות תהליך משופר שמשרת את המטרה טוב יותר.
קודם משכתי את החבילות שבהן אני הולך להשתמש:
import scrapy
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
import urllib.parse
import requests
Scrapy היא חבילת פייתון ליצירת העכביש (או סורק), ישנן חבילות אחרות, אך דרך הביצועים של Scrapy שכנעו אותי שזו החבילה שהכי מתאימה לפרוייקט, סקראפי בנויה על בסיס אסינכרוני (Asynchronous), במקרה הזה הכוונה היא שאקבל סריקה מהירה יותר, חשוב במיוחד באתרים גדולים.
Rule ו-LinkExtractor מאפשרות להנחות את העכביש בשורת קוד אחת באילו לינקים לגלוש.
חבילת Urllin.parse מפענחת (Decode) כתובות שעברו הצפנה (Encode) בדרך כלל כתובות שמכילות אותיות שונות מאנגלית.
Requests תייצר בקשות לדפים ספציפיים בצורה פשוטה יותר, או כמו שכתוב באתר:
Requests: HTTP for Humans™
שלב א' - הגדרות עכביש וסריקה
class TestSpider(CrawlSpider):
name = "test"
allowed_domains = ["cerve.co"]
start_urls = ["https://cerve.co"]
rules = [Rule (LinkExtractor(allow=['.*'], tags='a', unique=True), callback='parse_item', follow=True)]
שימו לב שבפתיחת פרויקט בדרך המקוצרת בדרך כלל מוגדר עכביש scrapy.Spider, לעומת זאת בקוד שלי השתמשתי ב-CrawlSpider, האופציות שלו רחבות יותר והוא מגיע עם האפשרות להגדיר חוקים (rules) שבהם העכביש ישתמש לשם מעבר בין דפים באתר.
הדומיין שמותר לסרוק (allowed_domains), אם לא תהיה הגבלה לדומיין ספציפי הוא יסרוק את כל הדומיינים שהוא יפגוש, לינק אחד לויקיפדיה ויש מצב שביקשנו ממנו לסרוק את כל האינטרנט.
הכתובת שממנה מתחילים (start_urls), זוהי פקודת חובה.
פקודת rules מגדירה את דרך ההתנהגות, לאן לגלוש ולאן להעביר את המידע על הדף הנסרק כדי שנוכל לדלות ממנו מידע / נתונים.
מכאן עולה השאלה מה העכביש עושה במצב שהוא נתקל בדף שהוא כבר היה בו? במקרה הזה אנחנו לא צריכים לדאוג, ב-Scrapy קיימת מערכת שעוזרת לזהות כפילויות ולחסוך בסריקות.
במקרה שלי אפילו עם המערכת המובנית לזיהוי כפלויות, נתקלתי בבעיה הראשונה, ה-Scrapy שלי לא ממש הקשיב להנחיה הזאת, לכן הוספתי את פקודת unique=True שמסננת כתובות שהעכביש כבר ביקר בהן.
שלב ב' - שליפה וחישוב אלמנטים חשובים בכל דף נסרק
def parse_item(self, response):
alllinks = response.css('a')
PRscore = 1 / len(alllinks)
if "nofollow" in response.css('head meta[name="robots"]::attr(content)').get('content'):
mrfollow = 'nofollow'
else:
mrfollow = 'follow'
if "noindex" in response.css('head meta[name="robots"]::attr(content)').get('content'):
mrindex = 'noindex'
else:
mrindex = 'index'
for link in alllinks:
href = link.css('a::attr(href)').get()
anchor = link.css('a::text').get()
rel = link.css('a::attr(rel)').get()
כאן מתחיל החלק המאתגר, הרי העכביש סורק כל כתובת שהוא נתקל בה, עכשיו צריך להגדיר אילו פרטים לחשב \ לשלוף מכל דף:
● שליפת כל תגיות הקישורים שבאותו דף – תגיות ה-a
● חילוק PR בין הקישורים שבדף
● זיהוי תגית Robots Follow / NoFollow
● זיהוי תגית Robots Index / NoIndex
● שליפת כתובת ה-URL (href) מהקישורים
● שליפת טקסט העוגן (Anchor Text) מהקישורים
● שליפת תגית ה-Rel מהקישורים
שלב ג' – הצגת הנתונים
בחרתי לייצא את הנתונים כקובץ אקסל היות וידעתי שהחוזק שלי מתבטא בניתוח נתונים באקסל ושכמות הנתונים קטנה יחסית, לעומת זאת אם הייתי עומד בפני פרוייקט שמצריך עבודה מהירה עם כמות נתונים מאסיבית, סביר להניח שהייתי ממשיך בהצגת הנתונים דרך כלים יעודיים בפייתון כדוגמת MatPlotLib, Pandas, ואחרים.
for link in alllinks:
href = link.css('a::attr(href)').get()
anchor = link.css('a::text').get()
rel = link.css('a::attr(rel)').get()
yield {
'page': urllib.parse.unquote(response.url),
'number of links': len(alllinks),
'meta robots follow': mrfollow,
'meta robots index': mrindex,
'links': urllib.parse.unquote(response.urljoin(href)),
'anchor': anchor,
'link-rel': rel,
'status': requests.get(response.urljoin(href)).status_code,
'page rank score': PRscore
}
בטבלת האקסל מופיעים:
● כתובת הדף הנסרק
● בוצע פיענוח כתובות שעברו הצפנה, כתובת מוצפנת נראית כך:
https://dudimazig.co.il/blog/seo/%d7%90%d7%99%d7%9a-%d7%a2%d7%95%d7%a9%d7%99%d7%9d-%d7%9e%d7%97%d7%a7%d7%a8-%d7%9e%d7%99%d7%9c%d7%95%d7%aa-%d7%9e%d7%a4%d7%aa%d7%97-%d7%9e%d7%9c%d7%90/
כתובת אחרי פיענוח נראית כך:
https://dudimazig.co.il/blog/איך-עושים-מחקר-מילות-מפתח-מלא/
● מספר הלינקים בדף
● האם תגית הרובוטס Follow / NoFollow
● האם תגית הרובוטס Index / NoIndex
● כתובות כל הקישורים המופיעים בדף
● גם פה בוצע פיענוח כתובות
● בנוסף תיקון מכתובת יחסית לכתובת אבסולוטית
● טקסט עוגן (Anchor Text) של כל קישור
● סטטוס HTTP של כל קישור (200, 300, 400, 500 וכל השאר)
● תגית ה-REL של כל קישור (Follow, Nofollow וכן הלאה)
● PageRank (PR) פנימי של כל קישור
כמו שרואים הקוד יחסית קצר ולא דרש הרבה זמן כתיבה, מה שכן דרש זמן היה להבין איך לחבר את הכל יחד בצורה תקינה ואיך לבדוק שהקוד לא מפספס מידע, למשל לייצר Request ל-כתובת URL ב-Scrapy היה קצת מורכב, לכן השתמשתי ב-Requests, אבל גם ב-Requests היו דרישות שדרשו טיפול כמו למשל שינוי הכתובות היחסיות לכתובות אבסולוטיות, פעולה שהצריכה גם את חבילת urllib.parse
תהליכים נוספים בדרך לסיום הקוד
אחד התהליכים היותר מעניינים שיצא לי לעבור עם כתיבת הקוד היה Debugging או בעברית ניפוי באגים, אני יודע, נשמע יותר טוב באנגלית.
בתהליך זה בודקים מדוע הקוד מחזיר רק חלק מהנתונים (או נתונים לא תקינים) ומאיפה זה מתחיל, מפרידים את פעולות העכביש ובודקים כל אחת מהן בנפרד, כך הטיפול הופך לקל יותר משמעותית.
דברים נוספים שבדקתי לפני סיום כתיבת הקוד (גם בגלל שאני סקרן וגם כי הפרפקציוניסט שבי לא נח לשניה):
האם אפשר לגרום לקוד לעבוד בצורה אסינכרונית (Async)?
כן, ספריית Scrapy בנויה על בסיס אסינכרוני, זה קורה לבד ולכן אין צורך לשנות כלום.
האם אפשר לגרום לקוד לעבוד מהר יותר?
כן, אבל זה דורש קצת תיחכום, שרתים היום מאטים חיבורים שמגישים יותר מידי בקשות בזמן קצר מאותו IP ומאותו User Agent. כדי לזרז את הסריקה צריך להשתמש ב-Proxy ו-User Agent שונים בכל אחת מהבקשות, בנוסף יש לשנות את הגדרות העכביש שישלח בקשות בקצב מהיר יותר, ב-Scrapy אפשר לעשות זאת דרך קובץ ה-Setting.py.
דרך נוספת היא להשתמש ב-Threads או ב-Multiprocessing, כמובן צריך לשים לב לאזהרות, למשל ב-Multiprocessing עלול להיווצר עומס על המעבד ולכן כדאי להתחיל ממספרים קטנים של חלוקת עבודה ולבדוק שהכל רץ תקין והמחשב שלנו לא "משתעל".
הנתונים ומה אפשר לבדוק בעזרתם
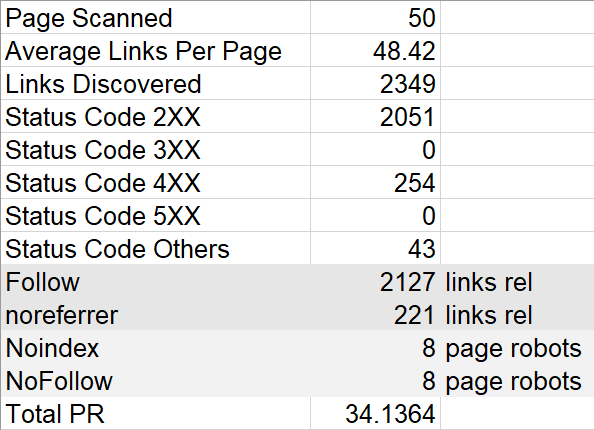
כדי שיהיה קל יותר להסתכל על הטבלה יצרתי לשונית חדשה שמסכמת מספר פרמטרים:
● מספר הדפים שנסרקו
● כמות קישורים ממוצעת לדף
● כמות קישורים כללית שהתגלו לאורך כל הסריקה (כולל כפולים)
● קישורים שמחזירים קוד 200
● קישורים שמחזירים קוד 300
● קישורים שמחזירים קוד 400
● קישורים שמחזירים קוד 500
● קישורים שמחזירים סטטוס HTTP 600 ומעלה
● כמות קישורים בעלי תגית Follow / NoFollow
● כמות קישורים בעלי תגית Rel אחרת –
במקרה הזה noreferrer
תגית Rel=noreferrer מוחקת את כותרת ה-HTTP כך שלמשל
באנליטיקס הכניסה תיחשב לכניסה ישירה (Direct) ולא דרך אתר מפנה (Referrals)
● דפים שמכילים Robots NoIndex
● דפים שמכילים Robots NoFollow
● סיכום ה-PR לאחר סינון של דפי 404 וקישורים שיוצאים מהדומיין
לפעמים קשה להבין אם הנתונים טובים או גרועים, במקרה כזה אפשר להסתכל על מבנה האתרים המתחרים, במיוחד אלה שמגיעים למקומות הראשונים.
- ישנם 254 קישורים שמובילים לדפי 404 – מבדיקת הנתונים שנסרקו רואים שהתקלה נובעת מלינקים עם רווחים, הטיפול הוא קל, מהיר וההשפעה גדולה מבחינת SEO, הרי שמדובר בשיפור חוויית המשתמש שרוצה לעבור מדף לדף.
חשוב לציין שבמקרה הזה לחיצה על הלינק שמופיע בדף המרונדר מובילה לדף תקין, אך בקוד הלינק מופיע בצורה לא תקינה וגוגל הולך לקרוא גם את זה.
- חלק מהלינקים הובילו לכתובות URL שלא מכילות את מילות המפתח המתאימות לתוכן הדף:
General > https://cerve.co/help/notice
Ordering > https://cerve.co/help/category
במבנה תקין הייתי מצפה לקישורים הבאים:
General > https://cerve.co/help/general
Ordering > https://cerve.co/help/ordering
- סיכום ה-PR הוא בערך 34, זה מרמז על כך שהאתר רק התחיל, 34 הוא מספר נמוך יחסית וכדי להצליח עם SEO כדאי לבנות עוד דפים, בדרך כלל דפי תוכן שמקשרים לדפים רלבנטיים. איך אפשר לדעת שסיכום ה-PR נמוך? בקלות, נכנסים לגוגל ובודקים את מספר 99ניקוד PR גבוה יותר.
כתוצאה מכך שלחתי מחקר מילות מפתח עם רעיונות לכתבות שמדברות אל קהל היעד ועם כל הדברים החשובים שכדאי לשים לב אליהם כשכותבים כתבות מסוג זה, במקרה הזה אלה כתבות B2B, התוכנית היא להגדיל את מספר הדפים בעזרת תוכן איכותי שקהל היעד של Cerve מחפש.
- את ה-PR בחנתי גם מול מספר הדפים, ה-PR מחושב כך שכל דף מכיל קרדיט של 1.0 והקרדיט מתחלק בין כל הקישורים (כולל קישורים חיצוניים), סיכום ה-PR הינו בסביבות 34, ומספר הדפים שנסרקו הוא 50, לאן נעלמו עוד 16 קרדיטים של PR?
חלק הלך לקישורים חיצוניים וחלק הלך לסאבדומיינים, ה-PR מחושב אך ורק לדפים שנמצאים בתוך Cerve.co, קישורים כמו app.cerve.co ו-grossiste.cerve.co נחשבים לקישור חיצוני ולשם חלק מה-PR הולך, פה זה בסדר היות ומדובר בסאבדומיינים ששייכים ל-Cerve.
חלק מה-PR הולך לקישורי 404 (ב-Cerve יש 254 קישורים כאלה) שאין להם כל תרומה לאתר והחלק האחרון נעלם לתוך קישורים שאותם תייגנו ב-NoFollow (ב-Cerve לא נמצאו קישורי NoFollow), כזכור, גוגל לא מעביר PR דרך קישורי NoFollow.
כרגע ישנם 50 דפים וקרדיט PR של 34, כלומר 32% מה-PR הולך למקומות ש-Cerve לא בחרו, הנתונים מבהירים כמה חשוב לדאוג לאתר תקין מבחינה טכנית ומתוכנן היטב מבחינת קישורים.
שימו לב! מספר הלינקים לאותו דף לא בהכרח אומרת שניקוד ה-PR שלו גבוה יותר, ישנה קורלציה בדרך כלל אך זה לא תמיד ככה, ישנם דפים שבהם פחות קישורים, קישור מדפים כאלה מעביר קרדיט PR גבוה יותר.
לדוגמה:
בדף עם 2 לינקים, כל לינק מקבל קרדיט PR של 0.50
בדף עם 50 לינקים, כל לינק מקבל קרדיט PR של 0.02
לכן, אם נדבר במונחי PR בלבד, לינק אחד מדף עם שני לינקים (0.5) שווה ערך ל-25 לינקים מדף שבו יש 50 לינקים (0.02).
אני כבר שומע הערה והיא נכונה, לא כל לינק מעביר את אותה כמות קרדיט, למשל לינק בתפריט ראשי מעביר יותר קרדיט מלינק בפוטר, לינק מדף חשוב באתר מעביר יותר קרדיט מדף ללא תוכן כלל, אך למטרת התנסות ראשונית עם פייתון החישוב הבסיסי הספיק כדי לספק מידע.
- כפילות תוכן – לכל הדפים יש כתובת כפולה עם הפרמטר ?_geo=1 והם יוצרים תוכן כפול, לדוגמה:
https://cerve.co/pricing
https://cerve.co/pricing?_geo=1
כרגע הבעיה מטופלת על ידי תגית קנוניקל לדף המקורי, אך במצבים כאלה של תוכן משוכפל הפתרון האידאלי הוא לבחור קישור אחד ולקשר רק בעזרתו. בטבלת האקסל שהקוד יצר היה קל לסנן את כל הלינקים שמצריכים תיקון ולשלוח למתכנת.
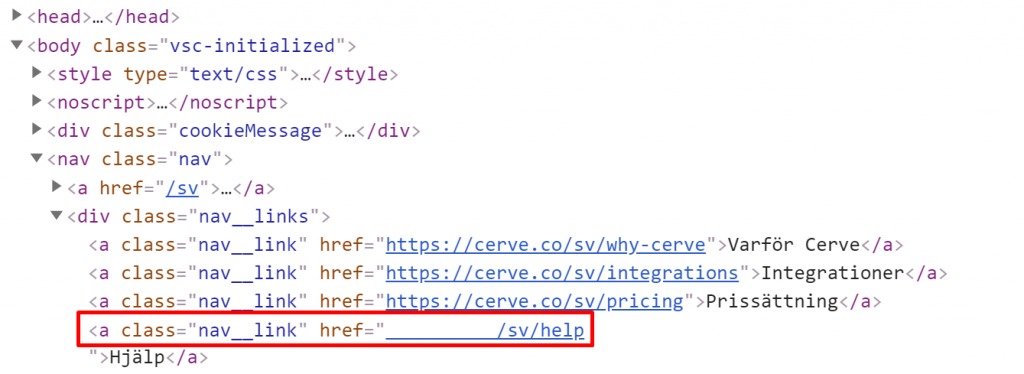
מקור הבעיה הוא המעבר בין שפות האתר – נמצא בפוטר:
- אתר Cerve מכיל מספר דפים מצומצם יחסית (50 דפים כולל כפילויות), תקלה מהסוג הזה באתר קטן היא פחות קריטית והקנוניקל הוא פתרון לא רע לבינתיים עד שהאתר יחליט לגדול. באתרים גדולים הבעיה יותר קריטית, כמה תקציבי סריקה היו הולכים לאיבוד אם האתר היה בסדר גודל של 200,000 דפים?
- האפליקציה של Cerve נמצאת על סאב דומיין, עובדה שהעלתה את השאלה האם זו הדרך הנכונה מבחינה שיווקית, השאלה עלתה כי האפליקציה מקבלת הרבה תשומת לב מהחברה ונמצאת בצמיחה, זה אומר שאם עיתון אינטרנטי או אתר שסוקר סטארטאפים יקשר לסאבדומיין במקום לאתר הראשי, אנחנו נפסיד חלק מהכח של הלינקים החשובים האלה.

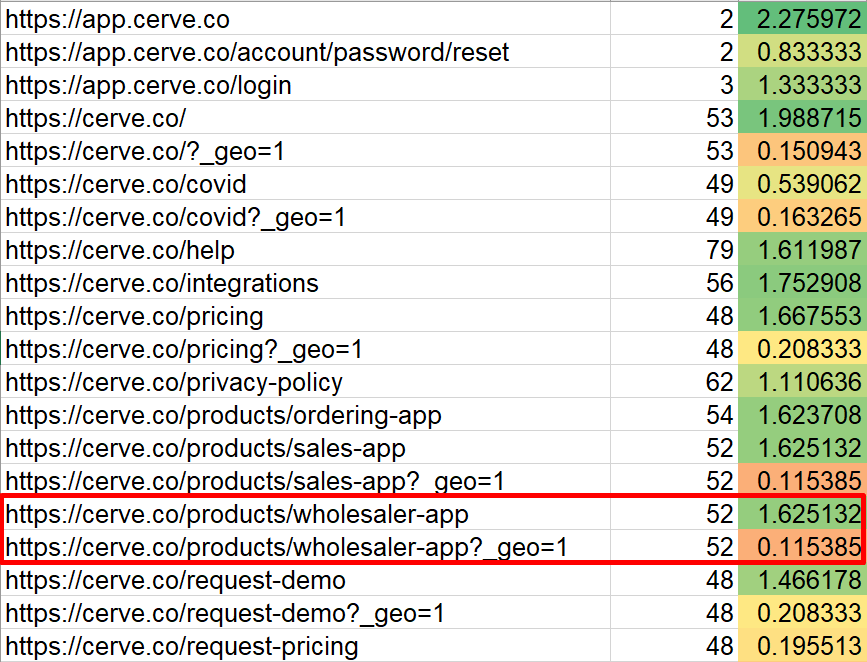
- מתוך כל הלינקים הכנתי רשימת URLs של דפים ייחודיים (בעזרת פקודת Unique ב-Excel, תודה שנזכרתם Microsoft), סיכמתי את ה-PR של כל אחד מהם, וידאתי שהדפים הכי חשובים מקבלים יותר PR מהשאר. שמתי לב שדף ה-Wholesaler לא קיבל מספיק PR למרות היותו דף חשוב וזו טעות אסטרטגית, Wholesalers הם הלקוח המרכזי של Cerve (וכמובן מילת מפתח מרכזית), הדף עצמו מקושר מכל דף באתר, הוא אמור להיות בין המובילים, אז למה זה קורה? בטבלת הדפים הייחודיים רואים מיד לאן הולך ה-PR, הוא מתחלק בין הדף הקנוני לדף הכפול, מה שיוצר את הכפילות הוא לינק שמכיל את הפרמטר "?_geo=1".
הדף הראשי של Wholesaler מקבל קרדיט של 1.625 כרגע, ועם שינוי כל הלינקים עם הפרמטר ללינקים ללא פרמטר, הדף יקבל קרדיט של 1.740, התחלה טובה של ניתוב תקין של PR באתר.
במקרה הזה הקנוניקל תקין ומכפה על הקישור הכפול בכך שהוא מעביר את כל הקרדיט לדף הקנוני, אך לא בכל האתרים יש קנוניקל שמכפה על טעויות מהסוג הזה אז חשוב ולבדוק ולתקן.
- אמנם זוהי הנחיה להרגל עתידי בריא אבל עדיין הנחיה חשובה לא פחות. בחלק מהמקרים טקסט העוגן בקישורים הוא טקסט גנרי שלא מסביר טוב יותר מה מצפה לגולש בלחיצה על הלינק, למשל ב-Cerve ביצעו מחקר מדהים שמראה איך וירוס הקורונה השפיע על תעשיית המזון, במקום להשתמש בטקסט עוגן כמו Download For Free אפשר לעזור לגוגל להבין טוב יותר במה מדובר אם היו הופכים את כל המשפט המציג את הדו"ח לטקסט עוגן, אפילו שזה קישור ארוך, התרומה ל-SEO תהיה גדולה יותר מDownload For Free , במקרה הזה הבעיה היא פחות קריטית היות והדף שאליו מגיעים בעת הלחיצה הוא דף עם תוכן וכותרות רלבנטיות שמסבירות במה עוסק הדף, אבל בלינקים שמקפיצים חלון או מובילים לדפים שבהם יש יותר מנושא אחד, ההרגל הזה יהיה אפקטיבי.

- בהמשך לבדיקות טקסט העוגן, ראיתי שרוב הקישורים באתר לא מכילים טקסט עוגן, פה חשדתי, בדרך כלל ישנם מספר לינקים ללא טקסט עוגן אך לא במספרים כאלה והם בטח לא הרוב. בדקתי לעומק ומצאתי שתי בעיות:
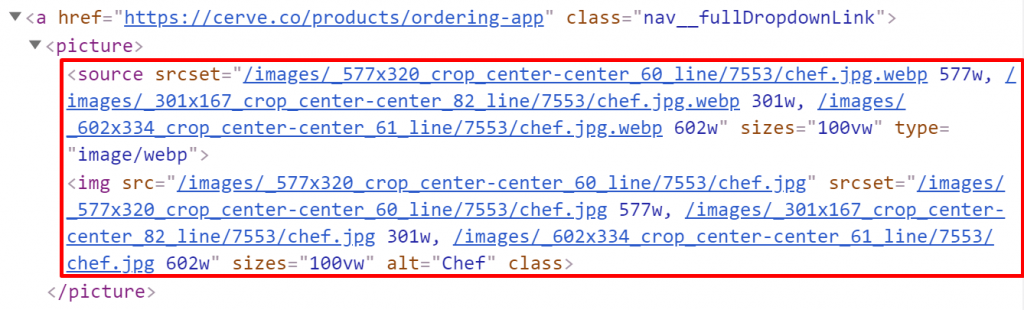
- העכביש צריך חידוד כי הוא לא מזהה טקסט שמופיע בתגיות פנימיות שנמצאות בתוך תגית קישור, כמו במקרה הבא:

- ראיתי שיש בקישורים תמונות רספונסיביות אבל הסינטקס של התמונות הרספטנסיביות לא היה תקין ובחירת הגדלים לא הייתה הגיונית (הגדלים היו לפי רוחב של 577 / 301 / 602), אפשר לראות בצילום המסך:
- כמובן שישנן הנחיות ברורות מגוגל איך מטפלים באתר רספונסיבי מבחינת תמונות, שלחנו הנחיות תקינות למתכנת, להלן ההנחיות מפי גוגל:
https://developers.google.com/web/fundamentals/design-and-ux/responsive/images
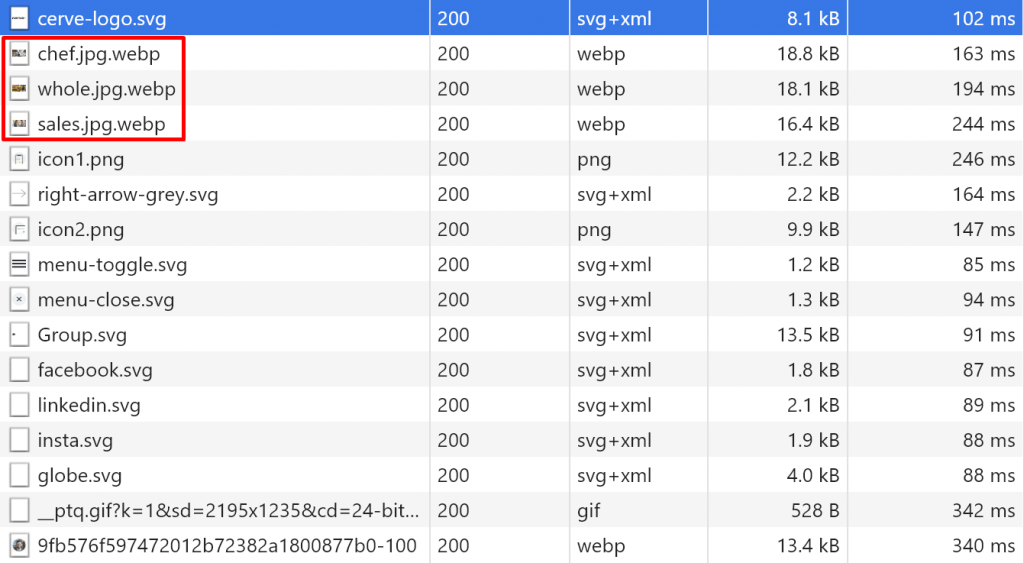
לפי הסינטקס עלה הסיכוי שאולי הדפדפן מוריד את אותה תמונה פעמיים אך בבדיקה ב-Google Chrome זה לא היה המקרה, אפשר לראות בצילום המסך שהתמונות נטענות פעם אחת בלבד:
- כמובן שישנן הנחיות ברורות מגוגל איך מטפלים באתר רספונסיבי מבחינת תמונות, שלחנו הנחיות תקינות למתכנת, להלן ההנחיות מפי גוגל:
כמו שאפשר לראות בחרתי להתמקד בהנחיות טכניות לפני הכל, כרגע Cerve בונים אתר עם מערכת שונה מאלה שאני מכיר, לכן צריך לבדוק שמבחינה טכנית מערכת ה-CMS מתפקדת בצורה שתורמת ל-SEO, אחרת הבעיות הקטנות שנוצרות באופן אוטומטי יהפכו לבעיות רציניות בהמשך שהטיפול בהם יבוא עם מחיר.
לדוגמה הפרמטר ?_geo=1 שיוצר תוכן כפול, אם לא היה קנוניקל או שגוגל היה מחליט להתעלם מהקנוניקל והיינו מקבלים מיקום גבוה בתוצאות עם חלק מהכתובות הללו, היינו צריכים לבצע הפניות 301 לאורך כל האתר, עם הזמן האתר יגדל וכמות הפניות גדולה מידי יכולה ליצור Delay בטעינת הדף או אפילו ליצור עומס במקרים מסויימים, שלא לדבר על זה שניהול כמות מאסיבית של הפניות היא מסורבלת ומצריכה זהירות, בדיקות ובזבוז זמן.
על כן בחרתי להתמקד בצד הטכני (מבנה לינקים, HTML, HTTP, CSS, מהירות טעינה וכדומה…) כדי שהבסיס יעבוד כמו שצריך לקראת העבודה השוטפת שכולנו מכירים: תוכן איכותי, מילות מפתח, קישורים פנימיים תקינים על טקסט עוגן נכון, כותרות, השבחת תוכן עם תמונות \ וידאו ועוד סוגי מדיה רלבנטיים לתחום של Cerve.
מה אפשר לעשות עם פייתון
עד עכשיו הקוד ביצע פעולות פשוטות כמו כל תוכנת סריקה שאנחנו מכירים: Screaming Frog, TechSEO360 וכן הלאה… אבל תחשבו לאן עוד אפשר להגיע אם האופציות האינסופיות ש-Python מציעה.
למשל הרצת הקוד הזה על אתרים מתחרים תבנה תמונת מצב של איך הם מנהלים את הקישורים וה-PR הפנימי, אפשר ללמוד מה המדדים הסטנדרטיים של המקומות הראשונים בתחום, ולהוציא רשימה של כל הדברים שאפשר לשפר.
נגיד שהאתר בעברית, באנגלית וברוסית והתוכן משתנה לשפה הנכונה בהתבסס על IP (לא תמיד רעיון טוב אבל רק בשביל הדוגמה), נוכל לכתוב קוד שיציג לנו אם האתר באמת מוצג נכון כשנסרוק אותו בעזרת Proxy מארצות הברית, רוסיה, ישראל וכן הלאה, בנוסף אפשר לבדוק איך האתר מתנהג אם נכנסים דרך IP מארצות הברית ומשנים את השפה לעברית, האם האתר מגיב נכון? האם הוא מבצע הפניות חזרה לשפה שתואמת ל-IP אחרי ששבוצע שינוי שפה באופן ידני? מה קורה אם אנחנו נכנסים ממובייל, האם האתר מגיב נכון גם לזה? ואם נכנסנו לדף ספציפי האם הדף התואם עולה או שהאתר מחזיר אותנו לדף הבית?
אם יש באתר המון כתבות, אפשר למשוך את כל הטקסטים באוטומציה ולהשתמש ב-Python בחבילות של ניתוח שפה (כמו לדוגמה NLTK) ולבדוק אם הטקסט מכיל מידע מספיק רחב \ מגוון, אם הוא כתוב נכון, שגיאות כתיב, האם חסרים פרטים חשובים וכן הלאה. דמיינו כמה אפשר ללמוד אם מריצים קוד כזה על המתחרים.
נגיד שלדעתי יש באתר רק לינק אחד שמקשר לכל הדפים, לדוגמה קישור "לדף הבא" בבלוג דימיוני כלשהו, אוכל להנחות את העכביש לבדוק לאילו דפים הוא מגיע אם הוא מתעלם מהלינק הספציפי הזה, כך אפשר לדעת אילו דפים לא מקושרים בדרך אחרת ואם אנחנו צריכים לעשות משהו כדי לעזור לגוגל להגיע לדפים חשובים לא רק דרך הלינק הזה, זהו כלי חשוב בהבנת מבנה האתר, תפריטים ראשיים, פוטרים, Pagination ועוד.
אם העליתי וידאו ל-YouTube והוא הצליח כל כך שהיו יותר מ-2000 תגובות, חשוב לי לדעת מה אנשים אומרים, אבל אני רוצה להתמקד בדברים השליליים שאמרו כדי שאוכל להוציא רעיונות ושיפורים לפני הוצאת הוידאו הבא, Python תשלוף את כל התגובות לרשימה, תנתח את הסנטימנט (Sentiment Analysis) של כל אחת מהתגובות כך שאוכל להתמקד רק במה שחשוב.